
作为一个SEO专业人士,你一定听说过ChatGPT和BARD——甚至你自己也用过它们。你可能也熟悉谷歌的一些机器学习模型,比如BERT和RankBrain。
这些都是机器学习的伟大应用。但是,机器学习对你的BAU(照常营业)任务或日常SEO待办事项的用处并不总是显而易见的。当涉及到在工作中使用机器学习时,还有道德问题,比如数据隐私和公平。然而,了解机器学习在搜索(以及在现实生活中)中的工作原理只会对你作为SEO专业人员有好处——不管你是不是技术人员。在这篇全面的文章中,了解与该技术相关的机器学习和伦理类型,然后从七个对我们的世界产生重大影响的机器学习示例中获得灵感。作为额外的奖励,在本文的最后,探索八个直接应用于SEO的机器学习示例。什么是机器学习?机器学习是人工智能(AI)的一个子集,它使系统能够在不需要明确编程的情况下学习和改进。这是通过使用大型数据集来训练模型中的参数来实现的。也许目前最著名的机器学习的例子是ChatGPT和BARD——虽然这篇文章不会关注他们,但我决定请他们俩给我解释一下什么是机器学习。以下是他们的回答:“机器学习是一种人工智能,它允许软件应用程序从数据中学习,并在没有明确编程的情况下更准确地预测结果。换句话说,它是一种教计算机从给定的数据中学习,然后根据学习做出决策或预测的方法。机器学习的目标是开发能够学习数据模式的算法,然后使用这些模式对新数据做出决策或预测。这是通过在已知输入和输出的数据集上训练机器学习算法,然后利用这些知识对新的、看不见的数据做出预测来完成的。机器学习的一些常见应用包括图像识别、自然语言处理、欺诈检测和推荐系统。 “机器学习是通过经验和数据的使用自动改进的计算机算法的研究。它被视为人工智能的一个子集。机器学习算法基于样本数据(即训练数据)建立模型,以便在没有明确编程的情况下做出预测或决策。
“机器学习是通过经验和数据的使用自动改进的计算机算法的研究。它被视为人工智能的一个子集。机器学习算法基于样本数据(即训练数据)建立模型,以便在没有明确编程的情况下做出预测或决策。
机器学习可用于各种任务,包括:
分类:将数据分类。例如,垃圾邮件过滤器可以将电子邮件分类为垃圾邮件或非垃圾邮件。回归:预测一个连续的值。例如,天气预报可能预测明天的温度。聚类:根据相似度将数据点分组在一起。例如,推荐系统可能会根据用户过去的购买行为将他们聚在一起。异常检测:识别异常数据点。例如,欺诈检测系统可以识别可能是欺诈的交易。机器学习是一种力量强大的工具,可以用来解决各种各样的问题。然而,重要的是要注意,机器学习算法的好坏取决于它们所训练的数据。如果数据有偏差,算法也会有偏差。此外,机器学习算法可能容易出现过拟合,即算法对训练数据学习得太好,不能很好地推广到新数据。尽管存在这些挑战,机器学习仍然是一个快速发展的领域,有着广泛的应用。随着我们可用的数据量不断增长,机器学习可能会在未来的生活中发挥更大的作用。 监督式学习
监督式学习
顾名思义,在监督式学习中,模型在监督下学习。它使用标记数据进行训练,并手动检查输出。机器从标记的数据中学习,然后用来做出未来的预测。一旦接收到输出,模型就会记住它,并将其用于下一个操作。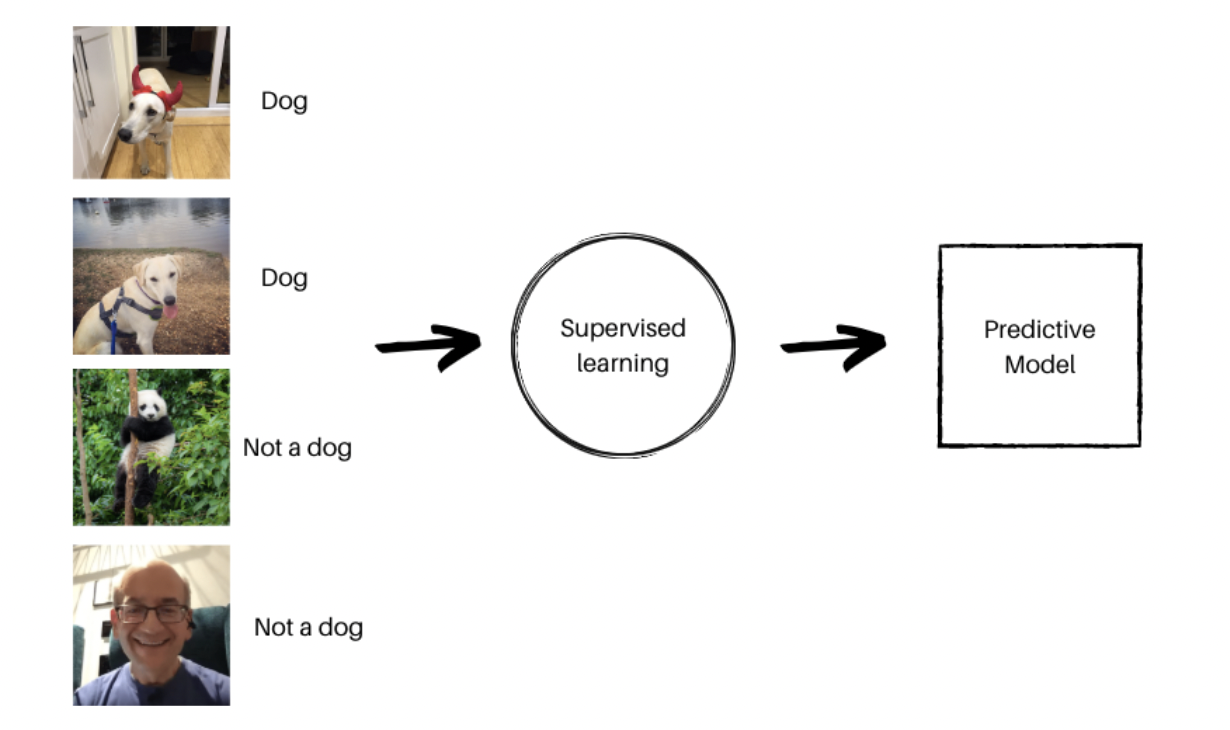
 图片来自作者,2023年4月
图片来自作者,2023年4月
监督学习主要有两种类型:分类和回归。
分类
分类是指输出变量是分类的,具有模型可以识别的两个或两个以上的类别;例如,真或假,狗或猫。这方面的例子包括预测电子邮件是否可能是垃圾邮件,或者一张图片是狗还是猫。在这两个示例中,模型将根据分类为垃圾邮件或非垃圾邮件的数据以及图像中是否包含狗或猫来训练。这是指输出变量是实数或连续值,并且变量之间存在关系。本质上,一个变量的变化与另一个变量的变化相关联。然后,模型学习它们之间的关系,并根据给定的数据预测结果。例如,根据给定的温度值或给定时间的股票价格可能是多少来预测湿度。无监督学习是指模型使用未标记的数据,在没有任何监督的情况下自行学习。本质上,与监督学习不同,模型将在没有任何指导的情况下对输入数据进行操作。它不需要任何标记的数据,因为它的工作是在输入数据中寻找隐藏的模式或结构,然后根据任何相似性和差异性对其进行组织。例如,如果给一个模型狗和猫的照片,它还没有训练到知道区分两者的特征。尽管如此,它仍然可以根据相似和不同的模式对它们进行分类。无监督学习也有两种主要类型:聚类和关联。聚类是将对象分类到彼此相似并属于一个集群的集群中,而不是与特定集群不同并属于另一个集群的对象的方法。这方面的例子包括推荐系统和图像分类。
关联是基于规则的,用于发现值集合中项目同时出现的概率。示例包括欺诈检测、客户细分和发现购买习惯。半监督学习通过使用一小部分标记数据和未标记数据来训练模型,将监督学习和无监督学习结合起来。因此,它适用于各种问题,从分类和回归到聚类和关联。
半监督学习可以在有大量未标记数据时使用,因为只有Y需要标记一小部分数据来训练模型,然后可以将其应用于剩余的未标记数据。Google使用半监督学习来更好地理解搜索中使用的语言,以确保它为特定查询提供最相关的内容。强化学习强化学习是指训练一个模型,通过采取顺序的决策方法来返回问题的最佳解决方案。它根据自己的经验试错来定义输出,对积极的行为给予奖励,如果没有朝着目标努力,就给予负强化。该模型与已设置的环境进行交互,并在没有人为干扰的情况下提出解决方案。然后,根据输出与目标的接近程度,引入人为干扰以提供正强化或负强化。例子包括机器人——想想在工厂装配线上工作的机器人——和游戏,AlphaGo是最著名的例子。这就是训练模型的地方,通过使用强化学习来定义赢得比赛的最佳方法,从而击败AlphaGo冠军。毫无疑问,机器学习有很多好处,机器学习模型的使用也在不断增长。然而,重要的是要考虑到使用这种技术所带来的伦理问题。这些问题包括:
机器学习模型的准确性,以及它是否会产生正确的输出。用于训练模型的数据中的偏差,会导致模型本身的偏差,从而导致结果的偏差。如果数据中存在历史偏差,那么这种偏差通常会在整个过程中重复出现。结果和整个过程的公平性。隐私——尤其是用于训练机器学习模型的数据——以及结果和预测的准确性。现实世界中的7个机器学习例子Netflix通过多种方式使用机器学习为用户提供最佳体验。该公司还在不断收集大量的数据,包括收视率、用户的位置、观看的时间长短、内容是否被添加到列表中,甚至某些内容是否被疯狂观看。然后使用这些数据进一步改进其机器学习模型。
在Netflix上的电视和电影推荐是个性化的,以满足每个用户的喜好。为了做到这一点,Netflix部署了一个推荐系统,该系统考虑了用户以前消费的内容、用户最常观看的类型以及具有相似偏好的用户观看的内容。Netflix发现,浏览屏幕上使用的图片对用户是否观看有很大的影响。因此,它使用机器学习来根据用户的个人偏好创建和显示不同的图像。它通过分析用户之前的内容选择,并学习更有可能鼓励他们点击的图像类型来做到这一点。
这只是Netflix在其平台上使用机器学习的两个例子。如果你想了解更多关于它是如何使用的,你可以查看该公司的研究领域博客。
2。Airbnb在全球各地以不同的价格点提供数百万个房源,Airbnb使用机器学习来确保用户能够快速找到他们想要的房源,并提高转化率。该公司部署机器学习的方式有很多种,并在其工程博客上分享了很多细节。由于房东可以上传自己的房屋图片,Airbnb发现很多图片都贴错了标签。为了尝试优化用户体验,它部署了一个使用计算机视觉和深度学习的图像分类模型。
项目Ect的目标是根据不同的房间对照片进行分类。这使得Airbnb能够按照房间类型显示房源图片,并确保房源信息遵循Airbnb的指导方针。为了做到这一点,它重新训练了图像分类神经网络ResNet50,使用少量标记的照片。这使得它能够准确地对上传到网站上的当前和未来的图像进行分类。为了给用户提供个性化的体验,Airbnb部署了一个优化搜索和发现的排名模型。该模型的数据来自用户粘性指标,如点击和预订。
列表从随机排序开始,然后在模型中给出各种因素的权重——包括价格、质量和受用户欢迎程度。一个列表的权重越大,它在列表中的显示位置就越靠前。这已经被进一步优化,包括客人数量、价格和可用性在内的训练数据也包含在模型中,以发现模式和偏好,从而创建更个性化的体验。
3。Spotify还使用了几种机器学习模型来继续革新音频内容的发现和消费方式。“Spotify使用一种推荐算法,根据其他用户的数据集来预测用户的偏好。这是由于人们听的音乐类型之间存在许多相似之处。
播放列表是它可以做到这一点的一种方式,使用统计方法为用户创建个性化的播放列表,例如发现每周和每日混合。然后,它可以根据用户的行为使用进一步的数据来调整这些。随着个人播放列表的创建也以百万计,Spotify有一个庞大的数据库可以使用——特别是如果歌曲被分组并标记为语义。这使得该公司可以向有相似音乐品味的用户推荐歌曲。机器学习模型可以为具有相似收听历史的用户提供歌曲,以帮助发现音乐。随着自然处理语言(NLP)算法使计算机比以往任何时候都能更好地理解文本,Spotify能够根据用来描述音乐的语言对音乐进行分类。它可以在网络上搜索特定歌曲的文本,然后根据上下文使用NLP对歌曲进行分类。这也有助于算法识别属于相似播放列表的歌曲或艺术家,这进一步有助于推荐系统。
4。虽然机器学习内容生成等人工智能工具可能是制造假新闻的来源,但使用自然语言处理的机器学习模型也可以用来评估文章并确定它们是否包含虚假信息。社交网络平台使用机器学习来查找共享内容中的单词和模式,这些单词和模式可能表明正在共享假新闻,并适当地进行标记。
5。健康检测
有一个神经网络的例子,它在10万多张图像上进行了训练,以区分危险的皮肤病变和良性的皮肤病变。当与人类皮肤科医生进行测试时,该模型可以从提供的图像中准确地检测出95%的皮肤癌,而皮肤科医生的这一比例为86.6%。由于该模型遗漏的黑色素瘤较少,因此确定其具有较高的灵敏度,并在整个过程中不断进行训练。机器学习和人工智能,再加上人类的智慧,有望成为一种有用的工具,用于更快地进行诊断。图像检测用于医疗保健的其他方法包括识别x光或扫描中的异常情况,以及识别可能表明潜在疾病的关键标记。
6。野生动物安全
保护助理是一个人工智能系统,用于评估偷猎活动的信息,以建立巡逻保护主义者帮助防止偷猎袭击的路线。这个系统不断被提供更多的数据,比如陷阱的位置和动物的目击情况,这有助于它变得更加智能。预测分析使巡逻单位能够确定动物偷猎者可能会去的地区。
SEO中的8个机器学习示例内容质量
机器学习模型可以通过预测用户和搜索引擎更喜欢看到的内容来提高网站内容的质量。该模型可以根据最重要的见解进行训练,包括搜索量和流量、转化率、内部链接和字数统计。然后可以为每个页面生成内容质量分数,这将有助于告知需要进行优化的地方,并且对于内容审计特别有用。
2。自然语言处理(NLP)使用机器学习来揭示文本的结构和含义。它通过分析文本来理解情感并提取关键信息。
NLP侧重于理解上下文,而不仅仅是单词。它更多的是围绕关键词的内容,以及它们如何组合成句子和段落,而不是关键词本身。
的整体情绪也被考虑在内,因为它指的是搜索查询背后的感觉。搜索中使用的单词类型有助于确定它是否被归类为具有积极,消极或中立的情绪。NLP的关键领域是;实体-表示可识别和评估的有形对象,如人、地点和事物的单词。类别-将文本分成不同的类别。显著性-实体的相关性。
Google有一个免费的NLP API演示,可以用来分析Google如何看到和理解文本。这使您能够确定对内容的改进。NLP还被用于审查和理解用于链接页面的锚文本。因此,确保锚文本的相关性和信息量比以往任何时候都更重要。确保每个页面都有自然的流程,标题提供层次结构和可读性。尽快回答文章提出的问题。确保用户和搜索引擎可以轻松发现关键信息。确保你有正确的拼写和标点符号,以显示你的权威和可信度。3. 谷歌的
人工智能和机器学习模型应用于谷歌的许多产品和服务。它在搜索上下文中最流行的用法是理解语言和搜索查询背后的意图。由于机器学习模型和算法的使用,搜索技术的进步使事情发生了怎样的变化,这是很有趣的。以前,搜索系统只查找匹配的单词,甚至不考虑拼写错误。最终,创建了算法来查找识别拼写错误和潜在错别字的模式。谷歌在2016年证实有意成为一家机器学习公司后,在过去的几年里推出了几个系统。其中第一个是RankBrain,它于2015年推出,帮助谷歌理解不同的单词与不同的概念之间的关系。
这使Google能够进行广泛的查询,并更好地定义它与现实世界概念的关系。Google的系统通过在页面上看到查询中使用的单词来学习,然后它可以使用这些单词来理解术语,并将它们与相关概念相匹配,以了解用户在搜索什么。
神经匹配于2018年推出,并于2019年引入本地搜索。
这可以帮助Google通过查看页面上的内容或搜索查询来理解查询与页面之间的关系N页面内容或查询的上下文。
今天的大多数查询都使用神经匹配,并用于排名。BERT是“变形金刚双向编码器表示”的缩写,于2019年推出,是谷歌迄今为止推出的最具影响力的系统之一。
这个系统使谷歌能够通过审查页面上的整个单词序列来理解单词的组合如何表达不同的含义和意图。
BERT现在在大多数查询中使用,因为它帮助谷歌了解用户在寻找什么,从而显示与搜索相关的最佳结果。“多任务统一模型”的意思是多任务统一模型,于2021年推出,用于理解语言和搜索词的变化。“LaMBDA”Language Models for Dialog Application,简称LaMDA,是最新的模型,用于使Google能够进行流畅和自然的对话。
使用最新的技术来发现句子中的模式和不同单词之间的相关性,从而理解细微的问题,甚至预测接下来可能出现的单词。
4。预测性预取
通过将用户行为的历史网站数据与机器学习功能相结合,一些工具可以猜测用户可能会浏览到下一个页面,并开始预取必要的资源来加载页面。这被称为预测性预取,可以增强网站性能。预测性预取也可以应用于其他场景,例如预测用户最有可能查看或交互的内容片段或小部件,并根据该信息个性化体验。
5。运行SEO A/B测试是提供SEO变化影响的最有效方法之一,并且通过使用机器学习算法和神经网络可以生成统计上显着的结果。SearchPilot是一个由机器学习和神经网络模型驱动的SEO A/B测试的例子。
开始用桶装算法创建统计类似桶控制和变种页面来执行测试,一个神经网络模型预测预期流量页面测试正在运行。神经网络模型经过训练,可以考虑任何和所有外部影响,如季节性、竞争对手的活动和算法更新,它还将分析不同页面的自然搜索流量,并确定它们在整个测试过程中与对照组的表现如何。
这也使用户能够计算流量的任何差异是否具有统计意义。
6。机器学习可以通过两种方式帮助修复内部链接:更新失效链接:机器学习可以抓取你的网站,发现任何失效的内部链接,然后用最佳替代页面的链接替换它们。建议相关的内部链接:这些工具可以利用大数据在文章创建过程中以及随着时间的推移建议相关的内部链接。
另一个内部链接任务是内部链接审计。这包括分析到页面的内部链接的数量、链接与锚文本的位置以及页面的整体抓取深度。
锚文本分类也可以执行,以确定在所有文本中使用最频繁的短语,并根据主题对它们进行分类,以及它们是品牌术语还是非品牌术语。
7。作为SEO专业人士,我们理解图像替代文本的重要性。它们提高了使用屏幕阅读器的用户的可访问性,同时也帮助搜索引擎爬虫理解他们所在页面的内容。
语言视觉模型可用于自动为图像配标题,从而提供可作为所有文本使用的内容。我图片字幕用于描述图片中单个句子所显示的内容。
两种模型用于图像字幕,两者都同样重要。基于图像的模型将首先从图像中提取特征,而基于语言的模型将这些特征翻译成逻辑句子。在现实世界中,图像字幕的一个例子是Pythia深度学习框架。
8。其他值得回顾的文章集中在使用深度学习来自动化标题标签优化和使用深度学习的意图分类。如果你对机器学习如何在日常SEO任务中使用感兴趣,Lazarina Stoy的这篇文章是必读的——如果你想玩一些超级有趣的脚本,从Britney Muller收集的Colab笔记本是一个完美的开始。总结
机器学习并不局限于ChatGPT和BARD。机器学习有很多实际的应用,无论是在现实世界还是在搜索引擎优化领域——这些可能只是一个开始。虽然认识到与机器学习相关的道德问题是至关重要的,但它对SEO的未来有着令人兴奋的影响。


