
Yandex是俄罗斯市场份额最大的搜索引擎,也是全球第四大搜索引擎。2023年1月27日,它遭受了可以说是现代科技公司多年来遭受的最大的数据泄露之一,但这是不到十年来的第二次泄露。2015年,Yandex的一名前员工试图在黑市上以约3万美元的价格出售Yandex的搜索引擎代码。
今年1月最初的泄露披露了1922个排名因素,其中超过64%被列为未使用或弃用(取代和最好避免)。这个泄漏只是标记为内核的文件,但是随着SEO社区和我深入研究,发现了更多的文件,这些文件加起来包含大约17,800个排名因素。当涉及到Yandex的SEO实践时,我两年前写的指南在很大程度上仍然适用。和谷歌一样,Yandex一直公开其算法的更新和变化,以及近年来它是如何采用机器学习的。在过去的两三年里,值得注意的更新包括:
Vega(它使指数的大小翻了一番)。模仿(惩罚假冒品牌的虚假网站)。Y1更新(介绍YATI)。Y2更新(2022年底)。采用IndexNow。PF过滤器的新推出和假设更新。就我个人而言,这次数据泄露就像第二个圣诞节。
自2020年1月以来,我经营了一个SEO新闻网站,作为一种爱好,致力于在俄罗斯报道600多篇文章的Yandex SEO和搜索新闻,所以这可能是爱好网站的高峰事件。
我还在俄罗斯最大的SEO会议——优化会议上说过两次话。这也是一个很好的测试,可以看到Yandex的公开声明与代码库秘密的匹配程度。2019年,我与Yandex的公关团队合作,采访了他们搜索团队的工程师,并问了一些来自更广泛的西方搜索引擎优化社区的问题。你可以在这里阅读对Yandex搜索团队的采访。虽然Yandex主要以其在俄罗斯的存在而闻名,但该搜索引擎在土耳其、哈萨克斯坦和格鲁吉亚也有业务。这次数据泄露被认为是出于政治动机,是一名流氓员工的行为,其中包含了Yandex单片存储库Arcadia的一些代码片段。在44GB的泄露数据中,有许多与Yandex产品相关的信息,包括搜索、地图、邮件、Metrika、磁盘和云。在我写这篇文章(2023年1月31日)时,Yandex已经公开声明:
存档(泄露的代码库)的内容对应于存储库的过时版本-它与我们的服务和当前版本不同。重要的是要注意,发布的代码片段还包含仅在Yandex内部使用的测试算法,以验证服务的正确操作。
所以,这个代码库有多少被积极使用是值得怀疑的。Yandex还透露,在调查和审计期间,它发现了许多违反其内部原则的错误,因此很可能这些泄露代码的部分(目前正在使用)可能会在不久的将来发生变化。因素分类Yandex将其排名因素分为三类。
静态因素——与网站直接相关的因素(例如,入站反向链接、入站内部链接、标题和广告比例)。动态因素-与网站和搜索查询相关的因素(例如文本相关性,关键字包含,TF*IDF)。用户搜索相关因素——与用户查询相关的因素(例如,用户所在位置、查询语言和意图修饰符)。
文档中的排名因子被标记为匹配相应的类别,分别是TG_STATIC和TG_DYNAMIC,然后是TG_QUERY_ONLY、TG_QUERY、TG_USER_SEARCH和TG_USER_SEARCH_ONLY。根据到目前为止的数据,以下是我们能够做出的一些肯定和学习。这次泄露的数据太多了,很有可能在接下来的几周内我们会发现新的东西,建立新的联系。
这些包括:
PageRank(的一种形式)。在某些时候,Yandex使用了TF*IDF。Yandex仍然使用元关键字,这也在其文档中突出显示。Yandex有针对医疗、法律和金融主题(YMYL)的特定因素。它还使用了一种页面质量评分形式,但这是已知的(ICS评分)。来自高权威网站的链接对排名有影响。没有什么新的迹象表明Yandex可以在已经公开记录的过程之外抓取JavaScript。服务器错误和过多的4xx错误会影响排名。一天中的时间被考虑为一个排名因素。下面,我将详述从泄密事件中获得的一些其他肯定和教训。
在可能的情况下,我还将这些泄露的排名因素与与之相关的算法更新和公告联系起来,或者我们被告知它们具有影响力的地方。MatrixNet在几个排名因素中被提及,并于2009年宣布,然后在2017年被Catboost取代,后者在Yandex产品领域推出。
这进一步增加了直接来自Yandex和DenPlusPlus (Den Raskovalov)的因素之一的评论的有效性,即这实际上是一个过时的代码存储库。MatrixNet最初是作为一种新的核心算法引入的,它考虑了数千个排名因素,并根据用户位置、实际搜索查询和感知到的搜索意图分配权重。它通常被视为谷歌RankBrain的早期版本,而它们实际上是两个非常不同的系统。MatrixNet比RankBrain早6年推出。
MatrixNet也建立在此基础上,这并不奇怪,因为它现在已经有14年的历史了。2016年,Yandex推出了Palekh算法,该算法使用深度神经网络更好地匹配文档(网页)和查询,即使它们没有包含正确的常见关键字“级别”,但满足了用户的意图。
Palekh能够一次处理150页,并在2017年更新了Korolyov更新,该更新考虑了更多的页面内容深度,并且可以一次处理20万页。
从泄漏中,我们了解到Yandex考虑了URL结构,具体来说:
URL中存在数字。URL中尾随斜杠的数目(如果它们过多)。URL中大写字母的数量是一个因素。
页面的年龄(文档年龄)和最后更新日期也很重要,这是有道理的。除了文档年龄和上次更新外,数据中的许多因素都与新鲜度有关——特别是与新闻相关的查询。Yandex以前使用时间戳,不是为了排名目的,而是为了“重新排序”的目的,但现在这是分类的未使用过。
在不推荐的列中还使用了URL中的关键字。Yandex之前测量过,URL中搜索查询的三个关键字将是“最佳”结果。
内部链接和抓取深度
虽然谷歌已经公开表示,抓取深度并不是一个明确的排名因素,但Yandex似乎有一段活跃的代码,规定从主页可访问的url具有“更高”的重要性。
这反映了约翰·穆勒在2018年的声明,即谷歌对从主页上点击不止一次的页面给予“多一点权重”。排名因素还突出了网站链接结构中“孤儿”网页的特定令牌权重。2011年,Yandex发布了一篇博客文章,讨论了搜索引擎如何将点击量作为排名的一部分,以及SEO专业人士如何操纵指标来获得排名。
泄漏的特定点击因素包括:
URL的点击次数与搜索的所有点击次数的比率。同上,但按地区细分。用户为搜索而点击URL的频率是多少?操纵用户行为,特别是“点击劫持”,是Yandex内部的一种已知策略。Yandex有一个过滤器,被称为PF过滤器,它会主动寻找并惩罚那些参与这种活动的网站,使用脚本来监控IP相似性,然后是这些点击的“用户行为”——影响可能是显著的。
下面的截图显示了模仿用户点击被处罚后对有机会话(сессии)的影响。图片来自俄罗斯搜索新闻,2023年1月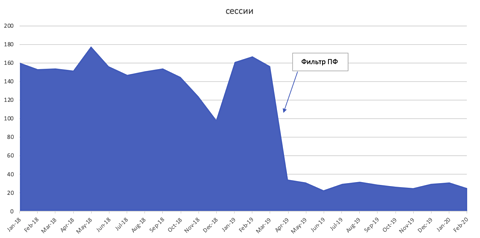 用户行为
用户行为
从泄漏中获取的用户行为是一些更有趣的发现。用户行为操纵是一种常见的SEO违规,Yandex已经与之抗争多年。在2020年优化会议上,Yandex网站管理员工具负责人Mikhail Slevinsky表示,该公司在检测和惩罚此类行为方面取得了良好进展。Yandex使用与打击点击率操纵相同的PF过滤器来惩罚用户行为操纵。
102的排名因子包含标签TG_USERFEAT_SEARCH_DWELL_TIME,并引用设备、用户持续时间和平均页面停留时间。
除了39个因素外,所有这些因素都被弃用了。
必应在2011年的一篇博客中首次使用了“停留时间”这个词,近年来谷歌明确表示,它不使用停留时间(或类似的用户交互信号)作为排名因素。YMYL(你的钱,你的生活)在谷歌内部是一个众所周知的概念,对Yandex来说并不是一个新概念。在数据泄露中,存在医疗,法律和金融内容的特定排名因素-但这在2019年Yandex网站管理员会议上公布的比邻搜索质量指标中得到了明显的披露。排名因素中有6个与为排名目的而使用Metrika数据有关。然而,其中一个被标记为不推荐的:
来自YandexBar (YaBar/Ябар)的类似访问者数量。花在相同相似访问者url上的平均时间。有Metrika计数器的页面的“核心受众”[已弃用]。用户从外部(从另一个非搜索站点)访问特定URL时在主机上花费的平均时间。从外部(从另一个非搜索站点)访问特定URL时,用户在主机上停留的平均“深度”(主机内的点击数)。域是否安装了Metrika。
在Metrika中,用户数据的处理方式不同。
不像谷歌Ana分析公司,有很多关于用户“忠诚度”的报告,将网站参与度指标与回访频率、访问间隔时间和访问来源结合起来。
例如,我可以一键看到一个报告,看到个人网站访问者的细分:
 来自Metrika的截图,2023年1月
来自Metrika的截图,2023年1月
Metrika也“开箱使用”热图工具和用户会话记录,近年来Metrika团队在能够识别和过滤机器人流量方面取得了良好的进展。对于Google Analytics,有一种观点认为Google没有使用UA/GA4数据进行排名,因为它很容易修改或破坏跟踪代码——但是使用Metrika计数器,它们更加线性,并且许多报告在数据收集方式方面是不可更改的。
在将Metrika数据作为排名因素之后;这些因素有效地证实了直接流量和付费流量(通过Yandex direct购买广告)可以影响自然搜索性能:
在所有传入流量中直接访问量的份额。绿色流量共享(即直接访问)-桌面。绿色流量份额(也就是直接访问量)——移动端。搜索流量——从搜索引擎到站点的转换。不通过链接(手动设置或从书签)访问网站的份额。独立访客的数量。来自搜索引擎的流量份额。与“新闻”相关的因素有很多,其中有两个提到了Yandex。直接消息。
Yandex News相当于谷歌新闻,但在2022年8月被卖给了俄罗斯社交网络VKontakte,同时出售的还有Yandex的另一款产品“Zen”。所以,目前还不清楚这些因素是否与不再由Yandex拥有或运营的产品有关,或者与新闻网站在“常规”搜索中的排名有关。Yandex在打击链接操纵方面和Google有类似的算法,并且在2005年推出了Nepot过滤器。从回顾反向链接排名因素和描述中的一些细节,我们可以假设为Yandex SEO构建链接的最佳实践是:
构建具有更自然频率和不同数量的链接。建立链接与品牌锚文本以及使用商业关键字。如果购买链接,避免从有混合主题的网站购买链接。下面是一个链接相关的因素列表,可以被认为是最佳实践的肯定:反向链接的年龄是一个因素。基于主题的链接相关性。从主页建立的反向链接比内部页面更重要。来自PageRank (PR)排名前100的网站的链接可以影响排名。链接相关性基于每个链接的质量。链接相关性,考虑到每个链接的质量,以及每个链接的主题。链接相关性,考虑到每个链接的非商业性质。包含查询词的入站链接的百分比。链接中查询词的百分比(直到同义词)。链接包含查询的所有单词(直到同义词)。链接中查询词数量的分散。然而,在规划、监控和分析反向链接时,有一些与链接相关的因素需要额外考虑:
一个网站的“好”与“坏”反向链接的比例。链接到网站的频率。主机之间进入SEO垃圾链接的数量。
数据泄露还显示,链接垃圾邮件计算器有大约80个活跃因素被考虑在内,还有一些不受欢迎的因素。这就产生了一个问题,即Yandex能够识别负面SEO攻击的能力有多好,因为它看到了好链接和坏链接的比例,以及它如何确定什么是坏链接。负面的SEO攻击也可能是一个短爆发(高频)链接事件,在这个事件中,一个网站将不知不觉地获得大量的低质量、非主题和潜在的过度优化的链接。
Yandex使用mac使用机器学习模型来识别私人博客网络(pbn)和付费链接,并在链接速度和获得时间之间做出相同的假设。通常,付费链接是在较长时间内生成的,这些模式(包括链接源站点分析)是Minusinsk更新(2015)引入的。有两个排名因素,都被弃用了,分别是SpamKarma和ization。“悲观化”是指将PageRank降低到零,并与严厉的Yandex处罚预期保持一致。
SpamKarma也与围绕Yandex惩罚主机和个人以及个别域名的假设保持一致。有许多与页面上的广告相关的因素,其中一些已经被弃用了(就像下面的截图例子)。
从描述中无法确切知道这个因素的思考过程,但可以假设,广告与可见屏幕的高比例是一个负面因素-就像如果广告混淆了页面的主要内容,或者是突兀的,谷歌会生气。将此与已知的Yandex机制联系起来,Proxima更新还考虑了页面上有用内容和广告内容的比例。谷歌能否借鉴Yandex的经验?Yandex和Google是完全不同的搜索引擎,有许多不同之处,尽管两家公司都有数十名工程师工作过。由于这种对人才的争夺,我们可以推断,这些建筑大师和工程师中的一些人将以类似的方式建造东西(尽管不是直接复制),并将他们从之前的构建迭代中学习到的知识应用到他们的新雇主身上。
就像西方世界一样,俄罗斯的搜索引擎优化专业人士一直在各种俄罗斯网络论坛上发表他们对泄密的看法。这些论坛的反应与SEO Twitter和Mastodon不同,他们更关注Yandex的过滤器,以及其他Yandex产品,这些产品被优化为更广泛的Yandex优化活动的一部分。同样值得注意的是,从数据中得出的一些结论和发现与西方搜索引擎优化界的发现相匹配。
俄罗斯搜索论坛的常见主题:
网站管理员询问有关最近过滤器的见解,例如Mimicry和更新的PF过滤器。年龄和相关性的一些因素,由于作者的名字不再在Yandex,并提及长期退休的Yandex产品。主要有趣的学习是关于使用Metrika数据,以及与Crawler & Indexer相关的信息。许多因素概述了DSSM的使用,理论上,DSSM已被2016年发布的Palekh所取代。这是Yandex在2016年宣布的一种利用机器学习的搜索算法。关于Yandex中ICS评分的争论,以及Yandex是否可以为网站提供更多流量并通过这样做影响其自身因素。泄露的因素,特别是关于Yandex如何评估网站质量,也受到了密切关注。
在俄罗斯搜索引擎优化社区中有一种长期存在的情绪,即Yandex经常在搜索结果中优先考虑自己的产品和服务,而不是其他网站,网站管理员会问这样的问题:
当它只是将其服务钉在页面顶部时,它为什么要这么麻烦?
在翻译松散的文档中,这些被称为魔法师或Yandex魔法师。在Google中,我们称这些搜索引擎结果页面(serp)为功能——就像Google酒店等。在2022年10月,Kassir(俄罗斯票票门户网站)要求Yandex赔偿由于收入损失,造成的“歧视性条件”,其中Yandex巫士从私人公司夺走了客户群。
这是在2020年集体诉讼的背景下,其中多家公司向联邦反垄断局(FAS)提出反竞争推广其自己的服务的案件


